-
 CombiCap: Combinación analítica de capas ráster y vectoriales
CombiCap: Combinación analítica de capas ráster y vectoriales
Acceso a este texto de ayuda como página web: CombiCap
Presentación
Este programa analiza y/o efectúa el cruce espacial de dos capas ráster, una capa ráster y una vectorial o dos capas vectoriales. Para la mayoría de combinaciones, las capas ráster deben ser categóricas, quedando los rásters de variación continua relegados a las posibilidades del enfoque mixto. Puede usarse un enfoque ráster de la combinación de capas, hecho que permite generar un nuevo ráster y/o un informe (en formato TXT y/o CSV [hoja de cálculo]) con tablas estadísticas de los cruces de los valores del ráster (identificados por sus categorías) o de los atributos de un campo de una capa vectorial (adicionalmente, para el caso de un campo numérico puede escogerse otro campo alfanumérico que describa los atributos). No obstante, un enfoque vectorial de la combinación también está disponible. En este último caso, se combinan todos los registros de la base de datos pero no se generan estadísticas.
Enfoque vectorial
Tanto si se indican dos capas vectoriales de
entrada, una capa vectorial y un ráster o dos rásters categóricos, se podrá
optar por un enfoque vectorial de la combinación de capas. En este caso, el
fichero vectorial de salida, su tipo y contenido dependerán del fichero de
entrada. Así, un ráster categórico puede considerarse como un fichero de
polígonos con el valor del ráster como único atributo temático vinculado a
un tesauro de categorías. La aplicación RasTop incluye más detalles sobre esta equivalencia. Una excepción la
constituyen los casos IMG + PNT = PNT (o IMG + NOD = PNT) y IMG + POL = POL que serán comentados
en el apartado enfoque mixto.
- POL + POL = POL
- IMG + IMG = POL
- El fichero de salida es un fichero de polígonos que se
obtiene de la fragmentación del espacio producida por la unión de los
bordes de los ficheros de polígonos originales. Cada fragmento hereda
todos los atributos de ambos polígonos origen que lo contienen.
- POL + ARC = ARC
- IMG + ARC = ARC
- Cada arco es partido en fragmentos a partir de los bordes del fichero
de polígonos derivado del IMG. Además de sus propios atributos de arco,
cada fragmento hereda los atributos del polígono que lo contiene.
- POL + ARC = POL
- IMG + ARC = POL
- La geometría del fichero de polígonos permanece inalterada pero sus
registros se ven enriquecidos por los atributos de cada arco que los
atraviesa o que está entera o parcialmente en su interior.
- POL + PNT = PNT
- La geometría del fichero de puntos permanece inalterada pero cada
punto adquiere los atributos del polígono que lo contiene.
- POL + PNT = POL
- IMG + PNT = POL
- La geometría del fichero de polígonos permanece inalterada pero sus
registros se ven enriquecidos por los atributos de los puntos contenidos
en cada polígono.
- POL + NOD = PNT
- El fichero de nodos se trata como un fichero de puntos donde cada
punto adquiere los atributos del polígono que lo contiene.
- POL + NOD = POL
- IMG + NOD = POL
- La geometría del fichero de polígonos permanece inalterada pero sus
registros se ven enriquecidos por los atributos de los nodos contenidos en
cada polígono.
Debe hacerse notar que en el caso de combinaciones vectoriales que tienen como resultado un vector, se
tienen en cuenta todos los atributos de las tablas principales de los dos
vectores así como sus relaciones con las tablas asociadas.
Cuando las capas analizadas presenten nombres de campo iguales en la
tabla principal, éstos serán modificados añadiendo _A para la primera capa y
_B para la segunda para poder diferenciarlos. Esto resulta especialmente
útil en el caso de estudios de los mismos parámetros en 2 momentos en el
tiempo (por ejemplo comparar dos mapas de vegetación de diferentes
fechas).
En las combinaciones de polígonos en las que los bordes no provienen de
la misma fuente pueden aparecer pequeñas regiones indeseadas que llamamos
micropolígonos. El programa permite la eliminación selectiva de este
artefacto definiendo un área mínima y/o una relación perímetro/área umbral.
Para más detalles puede consultarse MicroPol.
Enfoque mixto
IMG + PNT = PNT o IMG + NOD = PNT
Los ficheros de puntos o nodos pueden combinarse con rásters categóricos
o de variación continua para obtener un fichero PNT. En este caso, la
geometría del fichero de puntos permanece inalterada pero cada punto
adquiere el valor de la celda o celdas de ráster próximas al mismo un máximo
de un lado de píxel de distancia. Estos valores se heredan en forma de un
campo nuevo dentro de la base de datos. Es posible escoger entre la celda más
próxima o la moda de las celdas a menos de un píxel de distancia para
rásters categóricos o la interpolación bilineal entre 4 vecinos o bicúbica
entre 16 vecinos para rásters de variación continua.
IMG + POL =POL con estadísticos
En este caso se calculan valores estadísticos de los píxeles del ráster
dentro de cada polígono y estos valores estadísticos se transfieren a los
registros correspondientes de la tabla principal del polígono (sin alterar
la geometría de los objetos gráficos). En los bordes del polígono, los
valores del ráster se tendrán en cuenta según la combinación de los
criterios de área y punto central. Para más información sobre estos criterios se puede consultar TiraVec.
Los estadísticos implementados para un ráster cuantitativo continuo son:
número total de píxeles, media, desviación estándar, variancia, sumatorio,
mínimo, máximo y rango. Los estadísticos implementados para un ráster
categórico son: número total de píxeles, moda, porcentaje de la moda sobre el
total, índice de Shannon, mínimo, máximo y rango. Hay que remarcar que los
valores sindatos del ráster no participan en ninguno de los cálculos
estadísticos.
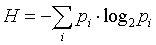
cálculo del índice de Shannon
Enfoque ráster
En caso de combinar dos imágenes de tipo ráster,
éstas deben corresponder al mismo ámbito geográfico, deben tener la misma
resolución y las mismas unidades referidas al mismo sistema de referencia.
En caso de combinar una capa ráster y una vectorial la primera define el
ámbito y la resolución de salida. En caso de combinar dos capas vectoriales,
se debe especificar el ámbito de la zona de estudio y la resolución del
ráster de salida. La ventana wCombiCa permite indicar un fichero ráster como
patrón para estos parámetros. Cuando se combinan dos imágenes ráster, éstas
pueden ser de diferente tipo (se excluye el tipo real ya que nunca debería
representar datos categóricos) y no importa el grado de compresión.
Como hemos dicho, el resultado puede ser un ráster y/o un informe. En
caso que se escoja generar un ráster, éste estará siempre en formato
extracomprimido y de tipo byte, integer o long según el número de
combinaciones que hayan resultado del cruce de las dos capas
iniciales.
Las nuevas categorías del ráster resultado se presentarán ordenadas por
las categorías de la primera capa, excluyendo aquellos cruces que,
aunque teóricamente posibles, no se den en ninguna posición geográfica. El
ráster resultado generará un valor sindatos en caso que en aquella posición
las dos capas tengan valor sindatos (ya sea porque el ráster de entrada
presenta valores indicados como tales, ya sea porque el fichero vectorial no
presenta ningún polígono en aquel punto). El valor de este sindatos dependerá
del tipo de salida escogido automáticamente. El cruce de un sindatos con
un valor permitido generará un valor permitido y se informará en la leyenda
de esta categoría que corresponde a este cruce especial. En la leyenda
del fichero resultado se especifican las categorías de que proviene cada
nueva categoría; si una categoría de un fichero origen no tiene descripción,
se especifica su valor numérico.
Informes
Para las capas ráster (o tratadas como ráster) se analiza
el cruce de cada valor con los que presenta la otra capa. Dado que las
capas vectoriales resultantes tendrán típicamente muchos campos y hacer las
estadísticas de todos resultaría confuso, solamente puede generarse un
informe si no se escoge capa de salida (indicando los campos de las capas
vectoriales a cruzar como ráster) o si la capa de salida es ráster; si la
capa de salida es vectorial, se pueden hacer consultas por atributo en MiraMon
para obtener las informaciones deseadas. Si bien cuando no se escoge capa de
salida se genera un informe relativo a sendos campos de las capas
implicadas, se debe tener en cuenta que los cálculos de superficie de cada
ocurrencia se obtienen a partir de la resolución de un hipotético ráster de
salida. En la primera tabla se recoge el número total de ocurrencias para
cada pareja de valores resultante de la combinación de las dos capas. A
continuación se generan dos tablas de porcentajes. Primeramente, se indica
cómo un determinado valor de la primera capa, se reparte en el cruce
con los diferentes valores de la segunda capa. Por tanto, el sumatorio de
una columna valdrá el 100%. La segunda tabla de porcentajes tiene el mismo
significado pero mostrando cómo se reparte la segunda capa sobre la primera;
en este caso es el sumatorio por filas el que valdrá el 100%.
Finalmente se generan dos tablas más, que recogen la superficie total de
cada cruce. La primera de ellas se expresa en las unidades de
referencia particulares de las capas que participen en el análisis
(parámetro "ResolutionUnits" del fichero .REL para rásters) y la
segunda en las unidades de superficie especificadas en el fichero de
parámetros de MiraMon (parámetro "UnitArea" del MiraMon.par).
El fichero en formato CSV detalla la misma información que el
fichero de texto. Este formato está preparado para ser leído por una hoja de
cálculo como por ejemplo Microsoft Excel®. Es un formato de texto donde un
carácter determinado actúa como separador de columnas. Este separador puede
especificarse en las opciones avanzadas de la aplicación wCombiCa, tomando
su valor por defecto del configurado como separador de listas en el Panel de
Control de Windows. De la misma manera que para el formato TXT, es posible
limitar la anchura del informe, evitando así sobrepasar el número máximo de
columnas soportado por la hoja de cálculo, cuando el número de categorías en
juego es bastante elevado.
En caso que se escoja un fichero de texto (formato TXT), éste
consta de cinco tablas de hasta tantas columnas como valores tiene la
primera capa y de hasta tantas filas como valores tiene la segunda capa. En
la fila y columna iniciales de cada una de estas tablas se especifican los
valores numéricos de cada categoría, y al final de la primera tabla se
listan sus descriptores correspondientes. La presentación puede paginarse
escogiendo el número máximo de columnas que caben en el ancho del informe;
su valor por defecto es 80 columnas (categorías).
Si se desea reducir el volumen de información de los informes, puede
aplicarse alguno de los parámetros para ignorar determinadas tablas
(/NO_FREQ, /NO_PERCEsNT, /NO_AREA).
Para más información se puede consultar la siguiente referencia:
Pesquer L, Masó J, Pons X (2000) Herramientas de análisis combinado ráster/vector en un entorno SIG. Aguado I, Gómez M (eds.) Tecnologías Geográficas para el Desarrollo Sostenible. Departamento de Geografía. Universidad de Alcalá, 2000: 53-73. IX congreso del Grupo de Métodos Cuantitativos, Teledetección y SIG de la Asociación de Geógrafos Españoles, Alcalá de Henares.

Caja de diálogo de la aplicación
|
| Caja de diálogo de CombiCap. |
Ejemplos gráficos
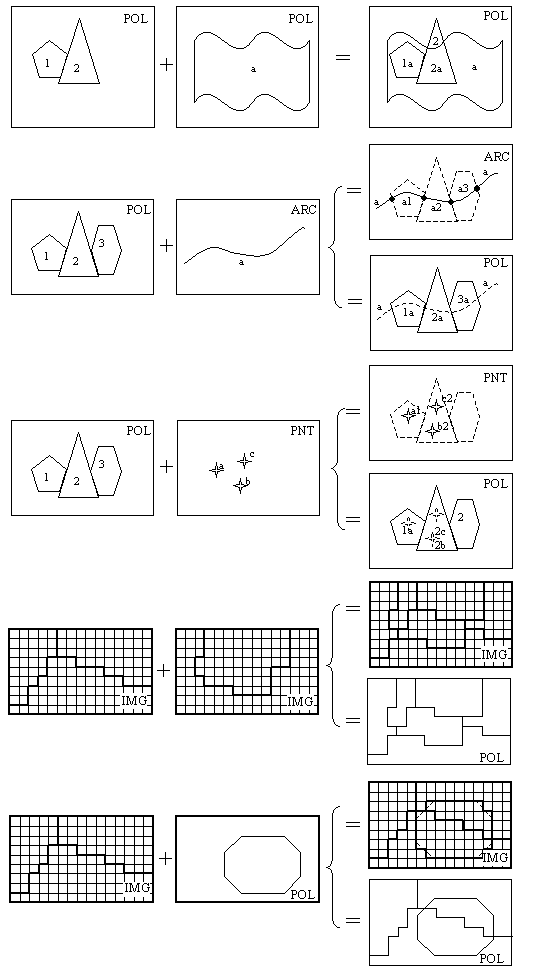 |
Esquema figurativo de las principales posibilidades
de la combinación analítica de capas. |
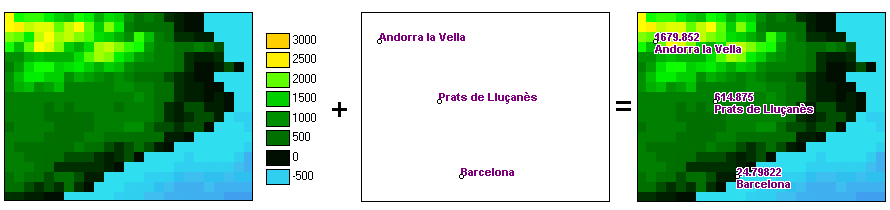 |
| Ejemplo de uso del modo mixto. |
Sintaxis
Sintaxis:
- CombiCap Capa1 Capa2 [/NCOL] [/SEPARA] [/NO_FREQ] [/NO_PERCENT] [/NO_AREA] [/AREA_MIN] [/AREA_PERI_MIN] [/NEXE_CRITERIS] [/FONDRE] [/ATRIB_ELIM] [/INTERPOL] [/OVR_RAS_POL] [/TAULA1] [/CAMP1] [/TAULA_CAT1] [/CAMP_CAT1] [/REPE1] [/TAULA2] [/CAMP2] [/TAULA_CAT2] [/CAMP_CAT2] [/REPE2] [/XMIN] [/XMAX] [/YMIN] [/YMAX] [/COSTAT] [/VORA] [/N_DECIMALS] [/ALGORISME] [/MEDIANA_EMPAT] [/EMANCIPA] [/REG_NODATA] /FCAPA /FTXT /FCSV
Parámetros:
- Capa1
(Capa 1 -
Parámetro de entrada): Es la primera capa que participa en la combinación.
- Capa2
(Capa 2 -
Parámetro de entrada): Es la segunda capa que participa en la combinación.
Modificadores:
/NCOL=
(Número de columnas)
Solicita el valor numérico de la paginación o tamaño máximo del informe medido en número de columnas (categorías). P. ej. /NCOL=120. Este parámetro sólo se tiene en cuenta en los ficheros de informe (TXT y CSV). El valor por defecto es 80. (Parámetro de entrada) /SEPARA=
(Separador)
Especifica el separador de listas necesario para el formato CSV. Ejemplo /SEPARA=; El valor por defecto es ';' (Parámetro de entrada) /NO_FREQ
(No ocurrencias)
Evita escribir las tablas de ocurrencias en el informe. (Parámetro de entrada) /NO_PERCENT
(No porcentajes)
Evita escribir las tablas de porcentajes en el informe. (Parámetro de entrada) /NO_AREA
(No superficies)
Evita escribir las tablas de superficies en el informe. (Parámetro de entrada) /AREA_MIN=
(Área mínima)
Área mínima permitida para un polígono. (Parámetro de entrada) /AREA_PERI_MIN=
(Mínima relación)
Mínima relación área/perímetro permitida. (Parámetro de entrada) /NEXE_CRITERIS=
(Nexo)
En caso de indicar los dos criterios, eliminar los polígonos que cumplen las dos condiciones a la vez (AND), o los que cumplen sólo una (OR). El valor por defecto es AND. (Parámetro de entrada) /FONDRE=
(Fusión)
Indica a qué polígono se asigna el espacio ocupado por el micropolígono que desaparece. Se debe indicar POL_GRAN si se quiere asignar el espacio al polígono contiguo de área más grande. El valor por defecto es FRONTERA_MES_LLARGA, que quiere decir que se elimina el arco más largo del micropolígono que desaparece. (Parámetro de entrada) /ATRIB_ELIM=
(Elimina atributos)
El polígono que absorbe el micropolígono hereda sus atributos si el valor es 1. El valor por defecto es 0, que quiere decir que los atributos del micropolígono se pierden. (Parámetro de entrada) /INTERPOL=
(Interpolación de ráster)
Es el criterio de interpolación de los valores del ráster:- VEI_MES_PROPER: no interpolar; escoger el más próximo. Es el valor por defecto en rásters categóricos.
- BILINEAL: Interpolación bilineal (4 vecinos). Es el valor por defecto en rásters de variación continua.
- BICUBICA: Interpolación bicúbica (16 vecinos). Segunda opción indicada para rásters de variación continua.
- MODA: Moda (4 vecinos). Segunda opción indicada para rásters categóricos.
(Parámetro de entrada) /OVR_RAS_POL=
(Ráster y polígono)
Indica el modo de este tipo de combinación:- VECTOR: enfoque vectorial, superposición, fragmentación y transferencia de atributos. Opción por defecto.
- ESTAD: enfoque mixto con transferencia de campos estadísticos.
- OCUR: enfoque mixto con transferencia del histograma por registro múltiple (en construcción).
(Parámetro de entrada) /TAULA1=
(Índice de la tabla de la capa 1)
Parámetros de rasterización de la capa 1 (sólo cuando la capa 1 no es un ráster): Es el índice, numerado desde 0, que indica cuál es la tabla de la base de datos que contiene el campo atributivo de interés: debe indicarse -1 si es la tabla principal o bien el índice del campo de la tabla principal sobre el que está vinculada la tabla asociada (normalmente un tesauro). (Parámetro de entrada) /CAMP1=
(Índice o nombre del campo de la capa 1)
Parámetros de rasterización de la capa 1 (sólo cuando la capa 1 no es un ráster): Es el índice del campo dentro de la tabla elegida (también numerado desde 0) o el nombre del campo de la capa 1 en formato a cadena a acceso a campo BD4. Estos criterios de indexación pueden conocerse con InfoTop o utilizando la propia interfaz Windows del programa (wCombiCa) y pulsando el botón ">>BAT...". (Parámetro de entrada) /TAULA_CAT1=
(Índice de la tabla de categorías de la capa 1)
Parámetros de rasterización de la capa 1 (sólo cuando la capa 1 no es un ráster): Es el índice, numerado desde 0, que indica cuál es la tabla de la base de datos que contiene el campo atributivo de interés para definir las categorías del ráster. (Parámetro de entrada) /CAMP_CAT1=
(Índice o nombre del campo de categorías de la capa 1)
Parámetros de rasterización de la capa 1 (sólo cuando la capa 1 no es un ráster): Es el índice del campo dentro de la tabla escogida para definir las categorías o el nombre del campo en formato a cadena a acceso a campo BD4. (Parámetro de entrada) /REPE1=
(Registro de la capa 1)
Parámetros de rasterización de la capa 1 (sólo cuando la capa 1 no es un ráster): Indica qué ficha (registro) se toma en caso de que existan múltiples registros sobre el mismo identificador gráfico (1 para la 1ª, 2 para la 2ª, etc). Si se indica con signo menos se empieza a contar por la última; si indica, por ejemplo, 2ª ocurrencia y ésta NO existe, no se rasterizará el polígono. El valor por defecto es 1. (Parámetro de entrada) /TAULA2=
(Índice de la tabla de la capa 2)
Parámetros de rasterización de la capa 2 (sólo cuando la capa 2 no es un ráster): Es el índice, numerado desde 0, que indica cuál es la tabla de la base de datos que contiene el campo atributivo de interés: debe indicarse -1 si es la tabla principal o bien el índice del campo de la tabla principal sobre el que está vinculada la tabla asociada (normalmente un tesauro). (Parámetro de entrada) /CAMP2=
(Índice o nombre del campo de la capa 2)
Parámetros de rasterización de la capa 2 (sólo cuando la capa 2 no es un ráster): Es el índice del campo dentro de la tabla elegida (también numerado desde 0) o el nombre del campo de la capa 2 en formato a cadena a acceso a campo BD4. Estos criterios de indexación pueden conocerse con InfoTop o utilizando la propia interfaz Windows del programa (wCombiCa) y pulsando el botón ">>BAT...". (Parámetro de entrada) /TAULA_CAT2=
(Índice de la tabla de categorías de la capa 2)
Parámetros de rasterización de la capa 2 (sólo cuando la capa 2 no es un ráster): Es el índice, numerado desde 0, que indica cuál es la tabla de la base de datos que contiene el campo atributivo de interés para definir las categorías del ráster. (Parámetro de entrada) /CAMP_CAT2=
(Índice o nombre del campo de categorías de la capa 2)
Parámetros de rasterización de la capa 2 (sólo cuando la capa 2 no es un ráster): Es el índice del campo dentro de la tabla escogida para definir las categorías o el nombre del campo en formato a cadena a acceso a campo BD4. (Parámetro de entrada) /REPE2=
(Registro de la capa 2)
Parámetros de rasterización de la capa 2 (sólo cuando la capa 2 no es un ráster): Indica qué ficha (registro) se toma en caso de que existan múltiples registros sobre el mismo identificador gráfico (1 para la 1ª, 2 para la 2ª, etc). Si se indica con signo menos se empieza a contar por la última; si se indica, por ejemplo, 2ª ocurrencia y ésta NO existe, no se rasterizará el polígono. El valor por defecto es 1. (Parámetro de entrada) /XMIN=
(X mínima)
Definición de la coordenada X mínima de la envolvente del fichero ráster de salida o del ráster temporal que dará lugar al vector resultado, cuando FicheroConEntidadesDiana es una capa vectorial. (Parámetro de entrada) /XMAX=
(X máxima)
Definición de la coordenada X máxima de la envolvente del fichero ráster de salida o del ráster temporal que dará lugar al vector resultado, cuando FicheroConEntidadesDiana es una capa vectorial. (Parámetro de entrada) /YMIN=
(Y mínima)
Definición de la coordenada Y mínima de la envolvente del fichero ráster de salida o del ráster temporal que dará lugar al vector resultado, cuando FicheroConEntidadesDiana es una capa vectorial. (Parámetro de entrada) /YMAX=
(Y máxima)
Definición de la coordenada Y máxima de la envolvente del fichero ráster de salida o del ráster temporal que dará lugar al vector resultado, cuando FicheroConEntidadesDiana es una capa vectorial. (Parámetro de entrada) /COSTAT=
(Lado del píxel)
Determina el lado de píxel del ráster resultado o temporal cuando FicheroConEntidadesDiana es una capa vectorial. (Parámetro de entrada) /VORA
(Borde)
En las combinaciones entre polígonos y arcos, o entre polígonos y puntos, (con salida vectorial) un punto o fragmento de arco que coincida exactamente con el borde de un polígono se considera que pertenece a los dos polígonos. Si no indica este parámetro se considera que el arco o el punto no pertenece a ninguno de los polígonos. (Parámetro de entrada) /N_DECIMALS=
(Número decimales)
Número de cifras decimales escritas en las coordenadas del fichero de salida. (Parámetro de entrada) /ALGORISME=
(Algoritmo de estructuración topológica)
Este modificador sirve para determinar el algoritmo que la aplicación utilizará para detectar las posibles intersecciones entre los segmentos de los elementos lineales y de los bordes de polígonos durante la estructuración topológica. Véase Algoritmos disponibles para la estructuración topológica (/ALGORISME) para una explicación más detallada y sugerencias sobre situaciones en las que es más adecuado uno u otro algoritmo.- ESCOMBRATGE (barrido): Basado en la intersección de segmentos de Bentley-Ottmann. Para líneas que intersecan en nuevos vértices.
- DIRECTE (directo): Basado en la exploración de las intersecciones de cada segmento contra todos los demás. Para polígonos explícitos o para capas con topología implícita (intersecciones ya convertidas en vértices).
- AUTOMATIC (automático): El programa decide automáticamente cuál de los dos algoritmos se utilizará. En ocasiones resulta más lento que el más rápido de los dos anteriores.
(Parámetro de entrada) /MEDIANA_EMPAT=
(Desempate de los cuantiles)
En caso de que se desee generar una capa de polígonos de salida con transferencia de los campos estadísticos, indica que tipo de desempate hacer en el caso de los cuartiles (media, primer cuartil, tercer cuartil, etc...). - 1: Valor alternado.
- 2: Valor inferior.
- 3: Valor superior.
- 4: Promedio de los valores centrales.
(Parámetro de entrada) /EMANCIPA
(Emancipa el fichero de salida)
En caso de que se desee generar una capa de polígonos de salida, indica que debe obtenerse un resultado emancipado de los arcos originales. (Parámetro de entrada) /REG_NODATA
(Incluir el sindatos como una categoría en la salida)
En el caso de la combinación de dos archivos ráster, indica que se desea añadir el valor de sindatos como una categoría en la salida. De este modo, el ráster resultante generará un valor sindatos cuando, en una posición determinada, ambas capas tengan valor sindatos (ya sea porque el ráster de entrada presenta valores marcados como tales o porque el archivo vectorial no presenta ningún polígono en ese punto). (Parámetro de entrada) /FCAPA=
(Nombre del fichero de la capa)
Es el nombre del fichero capa que generará el programa. Hay que escoger entre uno de los tipos permitidos: .IMG .POL .ARC .PNT (ver tabla de resultados posibles). Ejemplo /FCAPA=C:\RSULTADO.IMG (Parámetro de salida) /FTXT=
(Fichero estadísticas)
Es el nombre del fichero de texto donde el programa escribirá las tablas estadísticas. Puede tener cualquier extensión. (Parámetro de salida) /FCSV=
(Fichero tablas)
Es el nombre del fichero donde se volcarán las tablas estadísticas en formato CSV (formato de importación de hoja de cálculo). (Parámetro de salida)
